
ACL Reference Age
03 May 2022I reviewed a paper recently and while the ideas were sound and the implementation was thorough, something felt off. I couldn’t put my finger on it until I read the related work section: every reference had been published within the last 2-3 years.
This got me thinking. We joke about how nobody cites papers older than 5 years any more, but every generation believes that “back in my day, things were better”. How true is it actually?
This is an empirical question, and thanks to the amazing ACL Anthology, we can answer it. To do this, I used the Semantic Scholar API to gather the title, authors, and references for most ACL papers going back to the beginning (1979). This involved looking at this page for a while, trying to decide which papers to include (e.g. include main conference long and short, don’t include workshop papers). You can find my code and data here.
As an aside, this was an instructive process in itself. Did you know that the short paper track was only introduced around 2008?
Anyway, having gathered all this data, there are loads of interesting statistics to calculate.
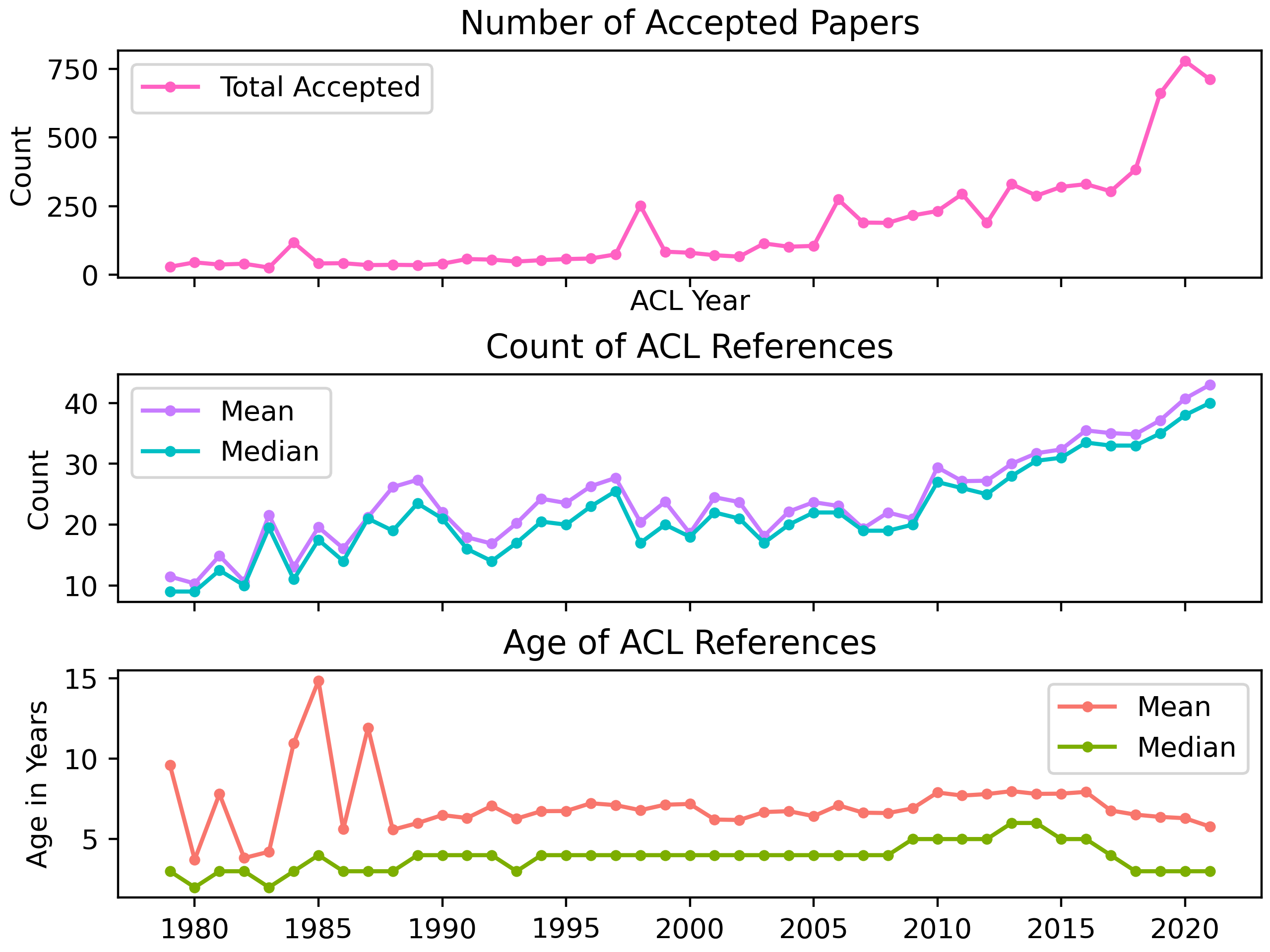
Number of accepted papers has always been growing, but it has skyrocketed in the last 3 years. Two interesting facts: 1) it was only 2006 when publication numbers started regularly going above 100, and 2) there have been more ACL papers published in 2014-2021 than in 1979-2013. Imagine having less than 100 ACL papers each year. I might actually read some instead of being paralyzed by the avalanche.
The spikes in publication numbers in 1984, 1998, and 2006 are because on those years ACL was held jointly with COLING.
Number of references has steadily increased since 2010. This is a fun one. Up until and including 2009, only one page was allowed for references, probably because of printing constraints. You can fit about 20 references on a page (unless you cite Universal Dependencies), which explains why the average hovered around 20 for a while. But in 2010, 2012, and then from 2016 onwards, papers were allowed unlimited references. Interestingly, the number of references has slowly grown since then. Is that just the field righting itself after years of reference starvation, or are we requiring unnecessary thoroughness?
Reference age (mean and median) has been decreasing since around 2015 and has reached a low not seen since the early 1990s. To be clear, I calculate reference age for a reference by subtracting reference year from conference year. For example, in an ACL 2017 paper, a citation to a paper in 2013 has reference age 4. Then for that year, I put every reference from every paper into a list and calculate statistics.
At first blush, this result seems to confirm my hypothesis: recent papers do tend to cite other recent papers. But much of this behavior can be explained by the dramatic growth in the number of publications per year and the number of references per paper. That is, in a world in which your topic has twice as many publications as before, and there’s no limit on references, it’s considered good practice (in fact, often recommended by reviewers) to cite all of them. This brings the average reference age down, even if all references to relevant “old” papers remain.
But looking from 2005 to 2014 or so, reference age increased even as publication and reference list sizes increased. This suggests that in those years, authors tended to not cite recent work, which may be a sign of stagnation.
If you look at the top 3 papers cited each year (see list below), you can see what happened. Up until 2014, Statistical Machine Translation references got the most action, and these largely came from the early 2000’s (reference age 10+ years). Then in 2015, word vectors burst onto the scene, from publications in 2013 or so (reference age 2+ years).
But even after 2014, increasing publication/reference list sizes don’t explain everything! These aggregate statistics decouple references from the paper that cited them. Let’s look at two other angles: median reference age by paper, and probability of oldest paper reference being less than N.
The graph below shows the former. Think about it this way, each paper in an ACL conference year is reduced to a single number: the median reference age. So if in 2021, you cite only BERT* papers, your median reference age will be about 2 or 3. But if you cite Penn Treebank style papers, your median reference age will be much higher. Having reduced each paper per year to a list of numbers, we can calculate percentiles.
After 2015, every percentile greater than 10 showed steep decline in median reference age. Even papers in the 95th percentile (those that cite the oldest papers), had medians that declined.
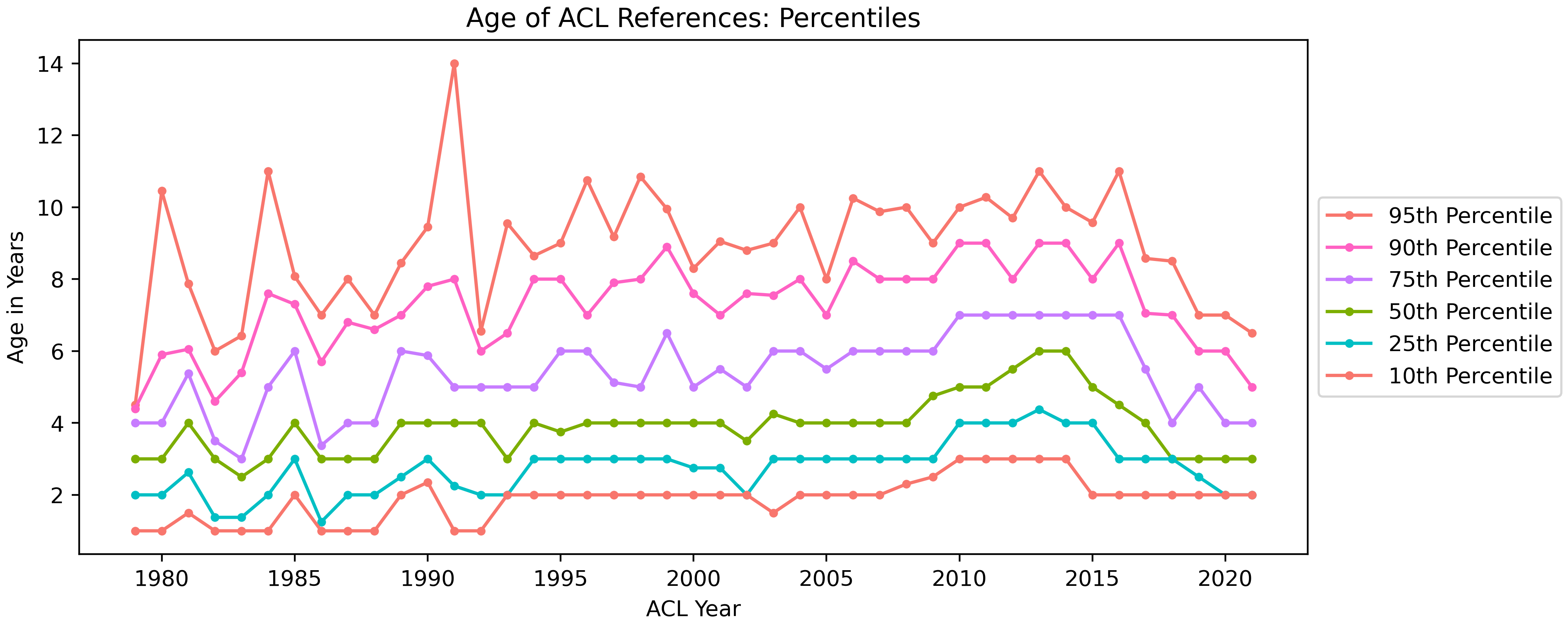
While this is interesting, it may still be dependent on increasing publication and reference list size.
Now, let’s represent each paper in a conference year by it’s oldest reference. This (mostly) controls for growing reference list sizes. Now, let’s calculate the probability that a randomly selected paper has oldest reference age less than N years, which controls for increased conference sizes. The graph below has the results!
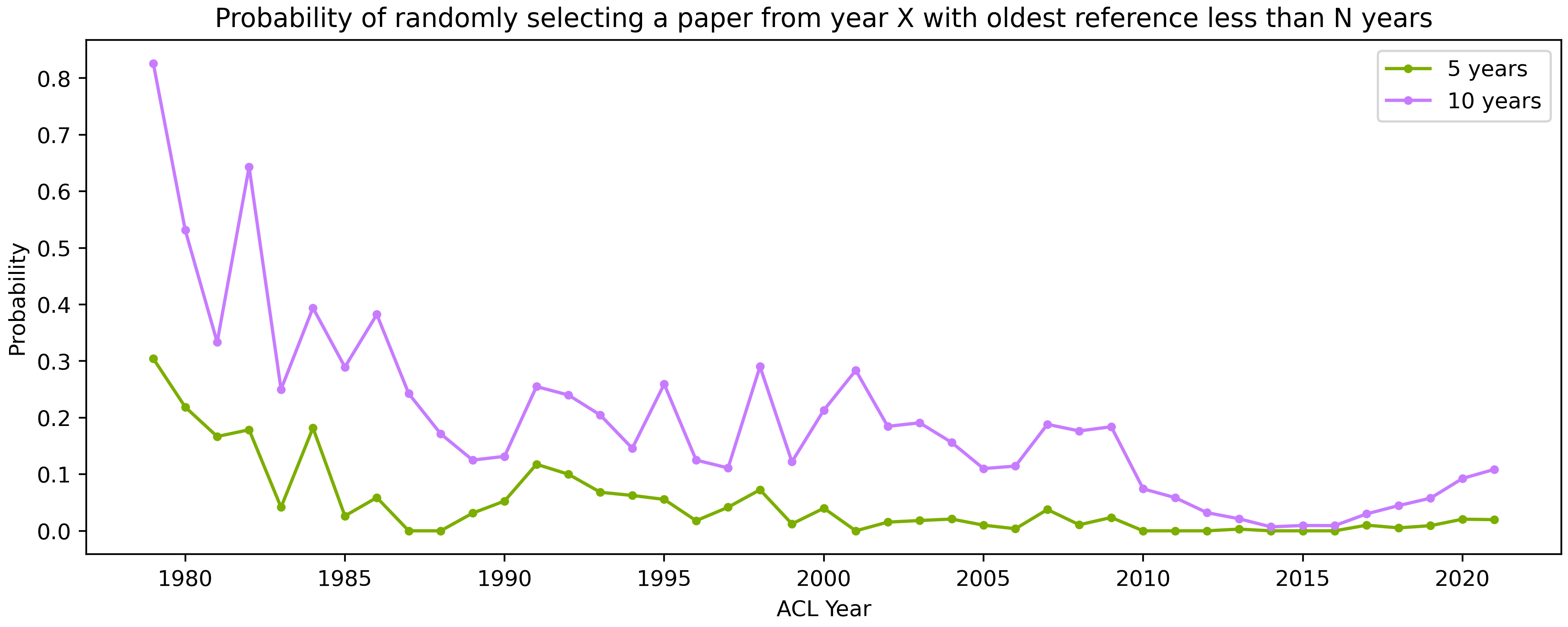
In a nascent field, you’d expect all citations to be young but getting older, and that’s exactly what we see back around 1979-1990. The probability of selecting a young paper continues to drop until about 2014, then starts to grow! That is, in 2014, if you grab a paper randomly, there’s about a 0.7% chance that the oldest reference will be less than 10 years old. Contrast that with 2021, when the probability is closer to 10%.
(In case you’re wondering, there were 2 papers in 2021 that had oldest reference age less than 3.)
Conclusion
Te recap, reference ages have been getting younger on average, although this is probably due to increased number of publications and reference page sizes. That said, we are seeing an increasing proportion of papers that fail to cite older work.
Again, you can find my code and data here. I invite interested readers to do their own analyses.
Caveats
- This analysis was entirely over ACL publications! It may be that EMNLP or NAACL have different patterns, although I doubt it.
- I personally only started reading and paying attention to NLP papers in 2012 or so. Some of my readers have been around longer, and probably have nuances or corrections for me. For example, thanks to Burr Settles for pointing out the unlimited references thing in 2010.
Update: comparing to “On Forgetting to Cite Older Papers”
Marcel Bollman graciously pointed out that I should probably have at least linked to his paper on a similar topic: On Forgetting to Cite Older Papers: An Analysis of the ACL Anthology, published in ACL 2020. Ironically, this paper is part of my dataset.
I’d encourage you to read their paper (and cite it), but here are my brief observations:
- On the whole, we have pretty similar conclusions! Old papers are still being cited, but the influx of new papers makes it harder to see that.
- My hypothesis about different conferences having similar behavior was largely correct, although very interesting to read about TACL and and CL having different patterns.
- I was wrong about unlimited references starting in 2010! ACL allowed unlimited references in 2010, 2012, and then from 2016 onwards.
- Their analysis goes back to 2010, but my analysis goes all the way back to 1979, which surfaces a few interesting patterns.
- We had different methods for gathering references. They parsed references themselves, I used SemanticScholar. It’s hard to say if one is better than another, but given similar conclusions, they are probably similar.
- We both included tables of Most Cited Papers by year – great minds, etc. etc.
- I had wondered if this kind of thing was publishable, and I’m happy to see the answer is Yes!
Bonus: Most Cited Papers by Year
I thought this would be fun to put out there. It’s interesting to watch the ebb and flow of topics over the years. In particular, I didn’t realize that machine translation was so dominant in NLP for so many years!