
Lexical features compared to Brown Cluster features for NER
16 Mar 2017It is generally considered the case that lexical features are important for NER (see here, for example). It is also common knowledge that Brown Clusters are useful features (see here, for example).
In our experience with low-resource languages, Brown Clusters are very effective. In fact, for some languages, it is better to not use lexical features. In our experiments with languages for which we have only a small amount of data, it seemed that word features were not useful at all, but Brown Clusters were especially effective.
In order to formalize this understanding, we did some experiments. First, using CoNLL 2003 English data. This has about 200K words of training data, and is well-studied. Second, we used Tamil data from the LORELEI project. The testing split is defined by Zhang et al 2016, and the testing data is the remaining documents, amounting to about 82K words.
For each language, we used all the available training data (Large), and then an artificially small subset (Small). For each training data size, we used all features, then removed Brown Clusters only, then removed lexical features only. The hypothesis is that features are important proportionally to how much that feature damage the score when omitted.
We used Illinois NER.
Our results are in the graph below.
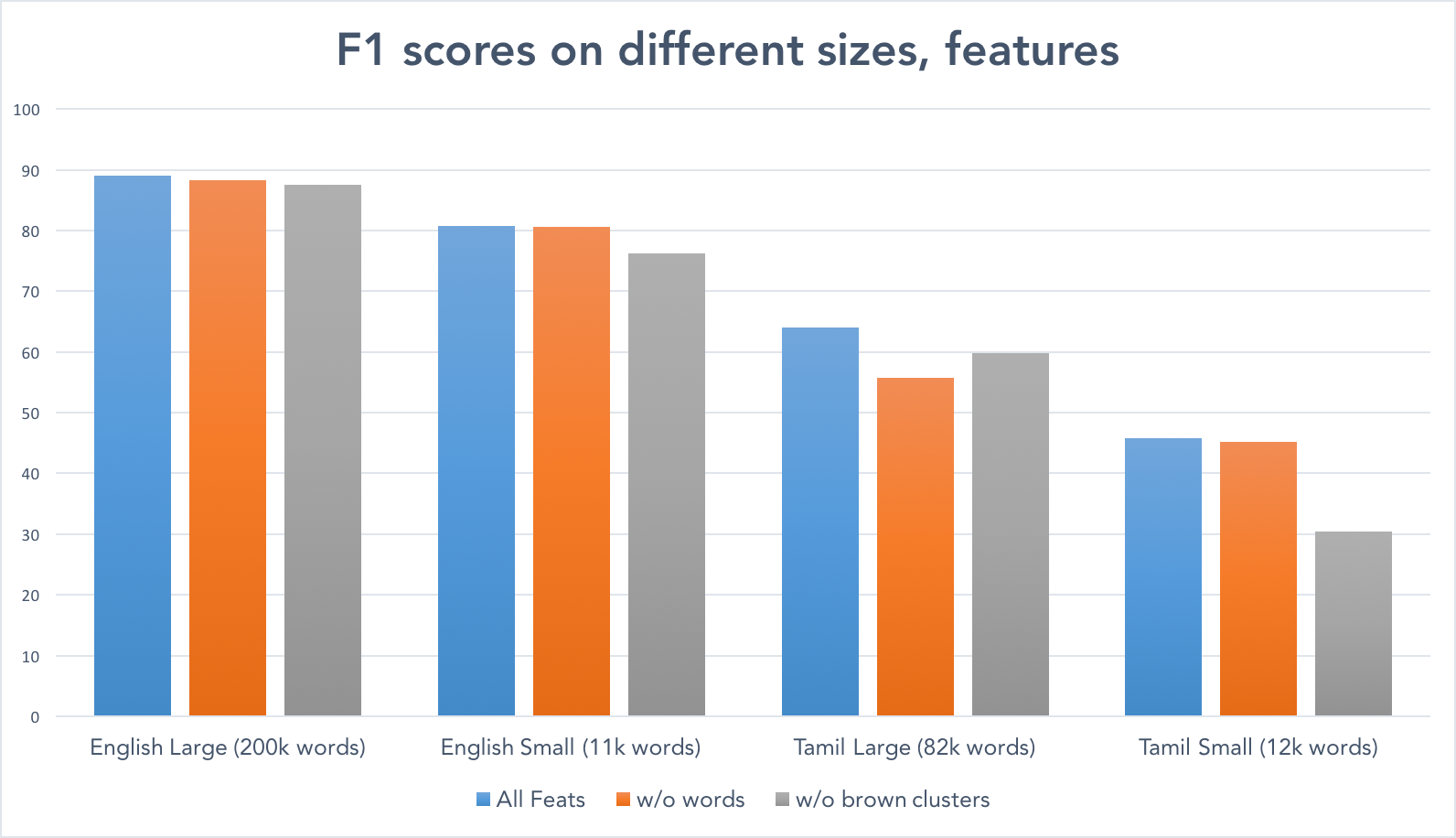
This suggests that at large data sizes, both Brown Clusters and lexical features contribute roughly equally, and not that much. For Tamil, it seems that removing lexical features is rather more damaging than removing Brown Clusters.
More interestingly, at small data sizes, it is clear that lexical features don’t add much, whereas Brown Cluster features are crucial. This is most obvious in Tamil (on the far right), where the omission of Brown Clusters causes a 15 point loss.
This may be because at small data sizes, a relatively small amount of vocabulary has been seen, and the classifier overfits to the data. On the other hand, Brown Clusters are able to generalize well.